AI Tokenomics 101: How to Slash Your LLM Bill by 50% Using Local SLMs
Marry Ava
AI is no longer experimental.
In 2026, it powers:
Customer support
Software development
Internal copilots
Enterprise search
Financial automation
Healthcare workflows
Security operations
Autonomous agents
But there’s a growing problem nobody talks about enough:
AI bill shock.
Companies that rushed to integrate GPT-powered applications are now facing monthly AI bills worth tens—or even hundreds—of thousands of dollars.
What looked affordable during prototyping becomes financially dangerous at production scale.
And the culprit is almost always the same:
Excessive API token consumption.
This has created an entirely new engineering discipline:
AI Tokenomics
Today, CTOs and engineering leaders are realizing that sustainable AI systems require:
Smart routing
Local inference
Open-weight models
Cost-aware orchestration
Data sovereignty strategies
The future of enterprise AI isn’t “send everything to GPT-6.”
Instead, modern AI architectures use:
Small Language Models (SLMs) locally
Large frontier models selectively
Hybrid inference pipelines
Private AI infrastructure
In this guide, you’ll learn:
Why AI costs are exploding
How local SLMs dramatically reduce inference spending
How hybrid AI routing works
Why enterprises are moving toward private AI systems
How to deploy your first local SLM in production
Let’s break down the economics of modern AI.
The Rise of AI “Bill Shock” in 2026
The biggest surprise for many startups wasn’t model quality.
It was the invoice.
Teams building AI products quickly discovered that:
Every request costs money
Long context windows are expensive
Multi-agent systems multiply token usage
RAG pipelines dramatically increase inference calls
AI copilots generate constant background requests
A simple chatbot prototype may cost:
$20/day during testing
But production workloads can suddenly become:
$10,000–$100,000/month
Especially when applications scale to:
Millions of users
Continuous workflows
Autonomous AI agents
Enterprise document retrieval systems
This is why AI cost optimization has become one of the most important engineering priorities in 2026.
Why Tokenomics is Now a Core Engineering Discipline
“Tokenomics” refers to the strategy of managing:
Token consumption
Model selection
Inference routing
Hardware utilization
Context optimization
In modern AI systems, bad architecture decisions directly impact profitability.
For example:
| Architecture Decision | Financial Impact |
|---|---|
| Sending every query to GPT-6 | Extremely expensive |
| Using 200k token contexts unnecessarily | Massive waste |
| Running RAG for every request | Higher latency + costs |
| No caching layer | Repeated inference spending |
| Poor prompt engineering | Token inefficiency |
Companies are now hiring engineers specifically focused on:
AI infrastructure efficiency
Inference optimization
GPU utilization
Local deployment systems
Because AI costs are becoming cloud-cost scale problems.
The Hidden Costs of RAG at Enterprise Scale
Retrieval-Augmented Generation (RAG) solved many hallucination problems.
But it also introduced hidden expenses.
A typical enterprise RAG pipeline involves:
Embedding generation
Vector database search
Context retrieval
Prompt construction
LLM inference
Multi-turn reasoning
At scale, these operations become expensive.
Especially when:
Documents are huge
Queries are frequent
Multiple agents are involved
Context windows grow endlessly
Many companies now realize:
Not every request needs a frontier model.
And that insight is changing AI architecture completely.
Small Language Models (SLMs) to the Rescue
The biggest AI infrastructure trend of 2026 is the rise of:
Small Language Models (SLMs)
These are compact, highly optimized models designed for:
Specific tasks
Fast inference
Low operational cost
Private deployment
Unlike massive frontier models with hundreds of billions of parameters, SLMs are:
Cheaper
Faster
Easier to fine-tune
Easier to deploy locally
And surprisingly powerful.
What Are SLMs and Why Are They Winning?
Small Language Models typically range between:
1B–15B parameters
Modern optimized SLMs can handle:
Summarization
Classification
Entity extraction
Code completion
Structured JSON generation
Customer support
SQL generation
Internal copilots
For many enterprise workloads, SLMs achieve:
80–95% of frontier model quality
At a fraction of the cost
That changes everything.
Open-Weight Models: Performance vs Parameter Count
One of the biggest misconceptions in AI is:
Bigger models are always better.
That’s no longer true.
Modern open-weight models are becoming extremely efficient.
Examples include:
Llama-family models
Mistral variants
Phi models
Gemma models
Qwen models
Highly optimized 7B–14B parameter models now outperform older massive models in many production tasks.
Why?
Because:
Better training data
Improved architectures
Fine-tuning efficiency
Quantization techniques
Retrieval augmentation
Specialized instruction tuning
have dramatically improved smaller models.
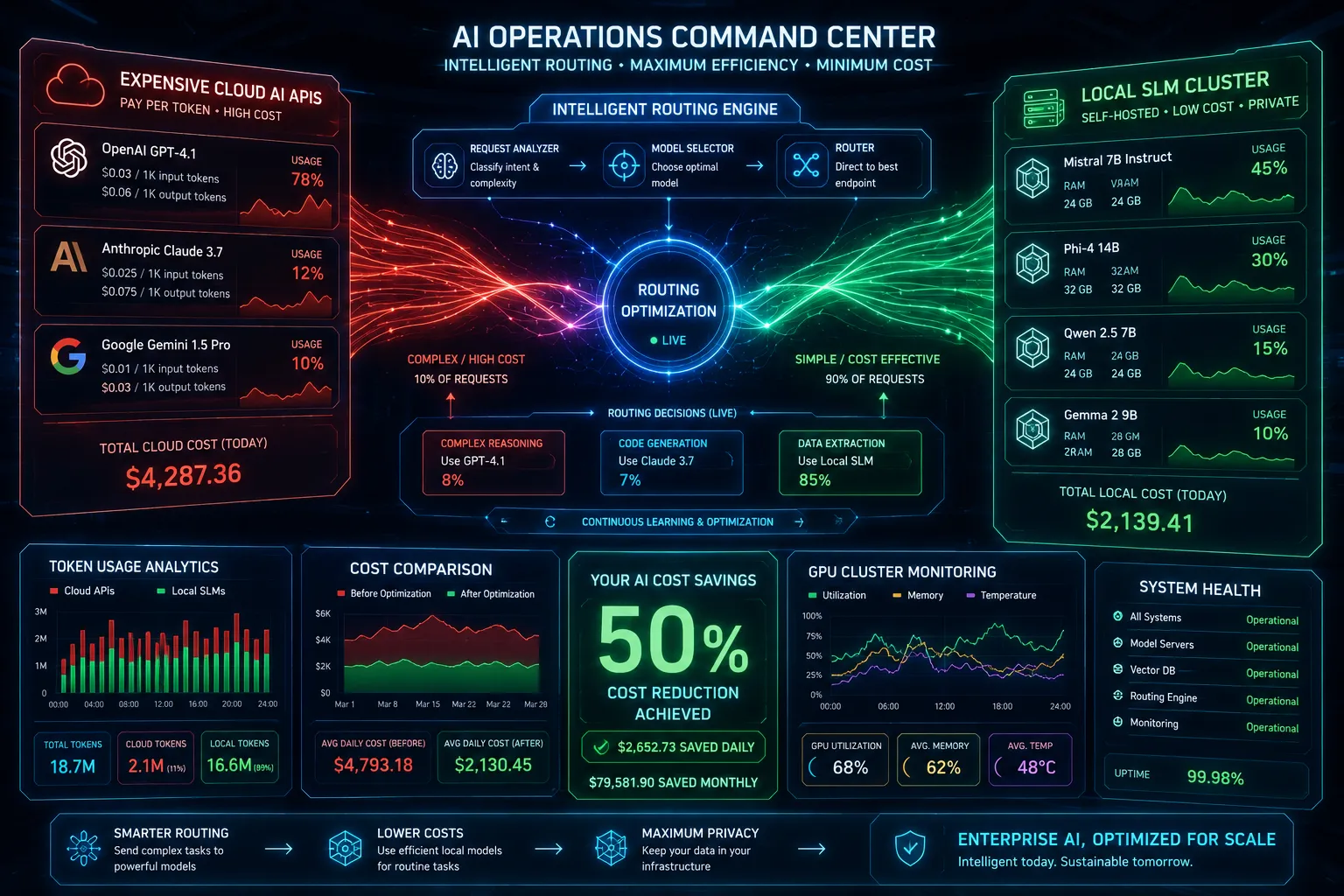
Architecting a Hybrid AI Routing System
The smartest AI systems in 2026 don’t rely on one model.
They use:
Hybrid AI Routing Architectures
This means:
Cheap local models handle simple tasks
Large frontier models handle complex reasoning
The result:
Massive cost savings
Lower latency
Better privacy
Improved scalability
Using Local Models for Routine Data Extraction
Most enterprise requests are repetitive.
Examples:
Extract invoice data
Summarize meeting notes
Categorize support tickets
Generate metadata
Parse PDFs
Convert documents to JSON
These tasks do NOT require expensive frontier models.
A local SLM can often perform them with:
Minimal latency
Zero API costs
Full data privacy
This is where companies save enormous amounts of money.
Falling Back to Large Frontier Models for Complex Reasoning
Some tasks still require powerful models.
Examples:
Advanced coding assistance
Deep reasoning
Multi-step planning
Research synthesis
Complex legal analysis
In hybrid systems:
Requests are classified first
Simple tasks stay local
Complex tasks route to GPT/Claude/Gemini-class models
This dramatically reduces overall inference spending.
A well-designed routing layer can reduce API costs by:
40–70%
without major quality loss.
The “Private by Design” Advantage
Cost isn’t the only reason enterprises are moving local.
Privacy is becoming equally important.
Sending sensitive enterprise data to external APIs introduces risks:
Regulatory concerns
Compliance issues
Data leakage fears
Vendor dependency
Cross-border data transfer restrictions
This is why local SLM deployment is exploding in:
Banking
Healthcare
Government
Legal tech
Defense
Enterprise SaaS
Solving Data Sovereignty for Fintech and Healthcare
Many industries legally cannot send confidential information to public AI endpoints.
Examples include:
Medical records
Financial transactions
Insurance claims
Government intelligence
Internal legal documents
Self-hosted AI infrastructure solves this.
Benefits include:
Full auditability
Air-gapped deployments
Compliance control
Private inference
Reduced legal exposure
This is becoming a major competitive advantage.
Running Models on Edge Devices
Another major trend is:
Edge AI Inference
Modern SLMs can now run on:
Laptops
Mobile devices
Industrial systems
IoT hardware
Edge servers
This enables:
Offline AI systems
Ultra-low latency
On-device privacy
Reduced cloud dependency
In 2026, many enterprise AI applications are becoming:
“Private-first by default.”
Step-by-Step: Deploying Your First Local SLM
Deploying local AI models is easier than ever.
Step 1: Choose the Right Model
Good starter models include:
Mistral 7B
Phi-4
Gemma
Qwen
Llama-family variants
Choose based on:
Latency requirements
VRAM availability
Task specialization
Quantization support
Step 2: Optimize with Quantization
Quantization reduces model memory usage.
Popular formats:
4-bit quantization
GGUF
AWQ
GPTQ
Benefits:
Lower GPU requirements
Faster inference
Lower power consumption
This makes local deployment much cheaper.
Step 3: Select an Inference Engine
Popular inference engines include:
vLLM
Ollama
TensorRT-LLM
llama.cpp
TGI (Text Generation Inference)
These tools simplify:
Local hosting
API serving
GPU optimization
Scaling
Step 4: Build a Routing Layer
A routing layer decides:
Which model should handle requests
Whether escalation is necessary
How to optimize costs
This is the core of:
AI cost optimization
Step 5: Add Monitoring and Observability
Track:
Token usage
Latency
GPU utilization
Cost per request
Cache hit rates
Routing efficiency
Without observability, token costs spiral quickly.
Hardware Requirements and Model Compression
You no longer need massive AI clusters to run useful models.
Example deployment options:
| Model Size | Hardware |
|---|---|
| 1B–3B | Consumer laptops |
| 7B | Single RTX 4090 |
| 13B | Dual GPUs |
| 30B+ | Enterprise GPU clusters |
Compression technologies like:
Quantization
Distillation
Sparse inference
are making AI deployment dramatically more affordable.
Open-Weight Models vs OpenAI in 2026
This debate is becoming central to enterprise AI strategy.
| Factor | Open-Weight Models | Frontier APIs |
|---|---|---|
| Cost | Low | High |
| Privacy | Excellent | Variable |
| Customization | Full control | Limited |
| Maintenance | Self-managed | Managed |
| Latency | Lower locally | Network dependent |
| Best For | Enterprise infrastructure | Complex reasoning |
The future likely belongs to:
Hybrid systems
—not one approach replacing the other.
Future of AI Infrastructure: Intelligent Cost-Aware Systems
The next generation of AI systems will be:
Cost-aware
Privacy-aware
Dynamically routed
Infrastructure-optimized
Soon, AI orchestration layers will automatically:
Choose the cheapest capable model
Compress prompts dynamically
Optimize context usage
Cache reasoning chains
Route based on confidence scoring
The companies that win in AI won’t simply have the smartest models.
They’ll have:
The smartest infrastructure.
Conclusion
The AI industry is entering its “cloud cost optimization” era.
And companies are learning a critical lesson:
Bigger models everywhere is not sustainable.
AI cost optimization is no longer optional.
It’s now a core engineering discipline.
By combining:
Local Small Language Models (SLMs)
Hybrid routing architectures
Open-weight inference
Intelligent orchestration
organizations can:
Cut costs dramatically
Improve privacy
Reduce latency
Gain infrastructure independence
The future of enterprise AI belongs to systems that are:
Efficient
Modular
Private
Economically scalable
And local SLMs are at the center of that transformation.
FAQ Section
What is AI cost optimization?
AI cost optimization refers to reducing expenses related to AI inference, token usage, GPU infrastructure, and API consumption while maintaining acceptable performance.
What are Small Language Models (SLMs)?
SLMs are compact AI models optimized for speed, low cost, and local deployment while still handling many enterprise AI tasks effectively.
How much money can hybrid AI routing save?
Well-designed hybrid routing systems can reduce LLM API costs by 40–70% depending on workload patterns and model selection strategies.
Are open-weight models good enough for production?
Yes. Modern open-weight models are increasingly production-ready for many enterprise tasks such as summarization, extraction, classification, and copilots.
Why are enterprises deploying local AI models?
Main reasons include:
Cost reduction
Data sovereignty
Compliance requirements
Lower latency
Infrastructure control